一、爬取豆瓣电影td数据代码
1 | #-*- coding:UTF-8 -*- |
二、爬取豆瓣电影-轮播图中数据的href数据
1 | #找到相应的轮播图数据的href |
1 | #-*- coding:UTF-8 -*- |
1 | #找到相应的轮播图数据的href |
1 | class CLASS_NAME: |
比如有一个类:Human,另外有一个Student类 现在用Student类继承于Human
1 | # Human类的构造函数: |
1 | # Student比Human类多一个属性studentnum |
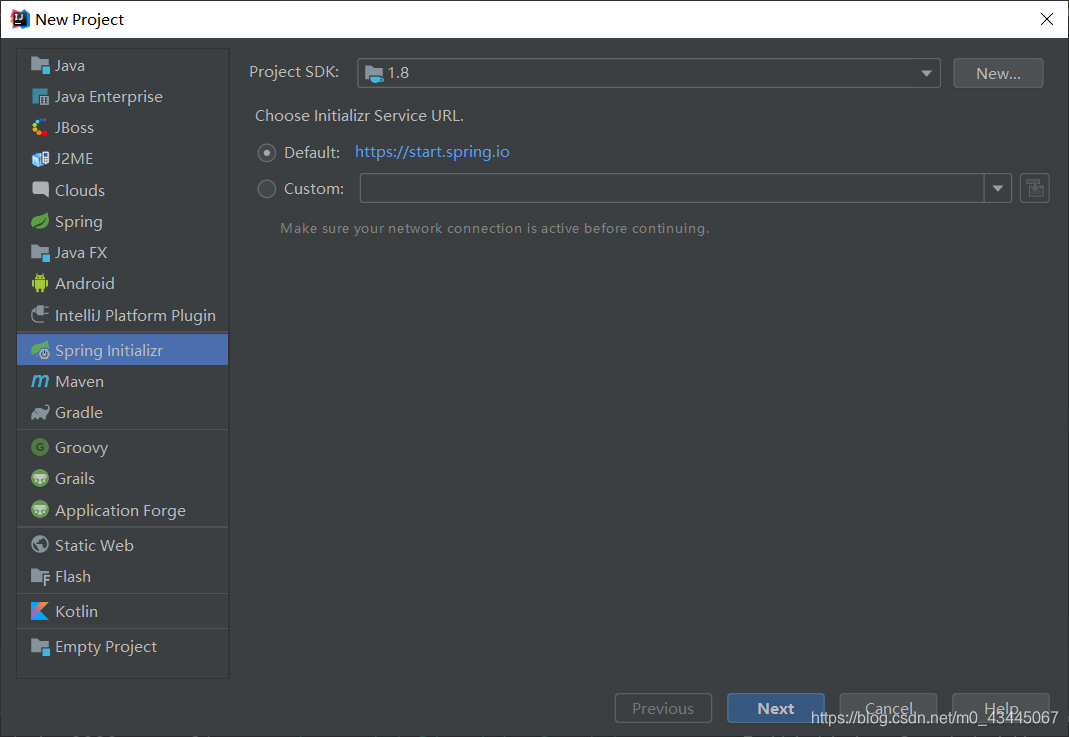
直接点next下一步;
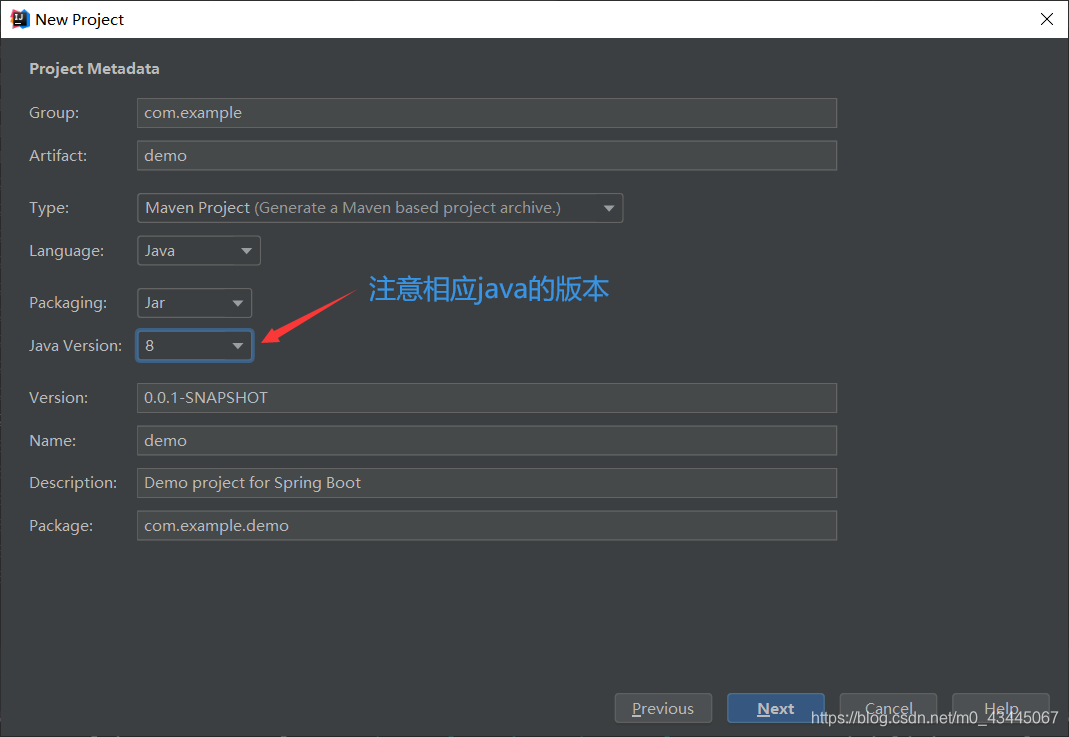
next点完,依赖后面再添加。
依赖删除,重新添加
①:spring-boot-starter-web
②:spring-boot-starter-thymeleaf
1、其中 static 放除pages以外的
2、templates 放pages
(数据来自ok-admin-master) 百度网盘有
存入之后,项目结构图为(记得加入index.html)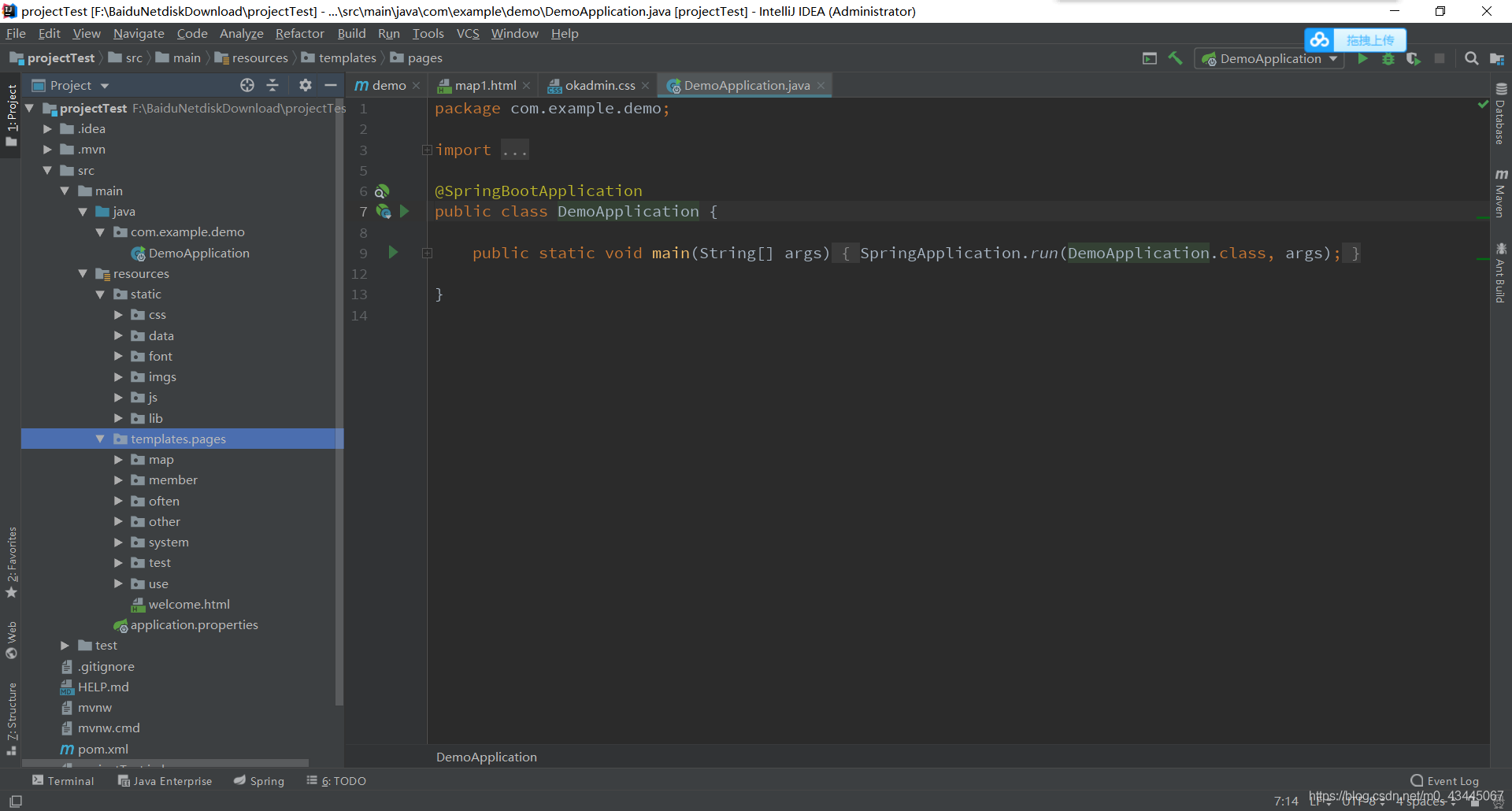
注意,启动时可能会报相应Test错误(由于改动了相应的依赖)
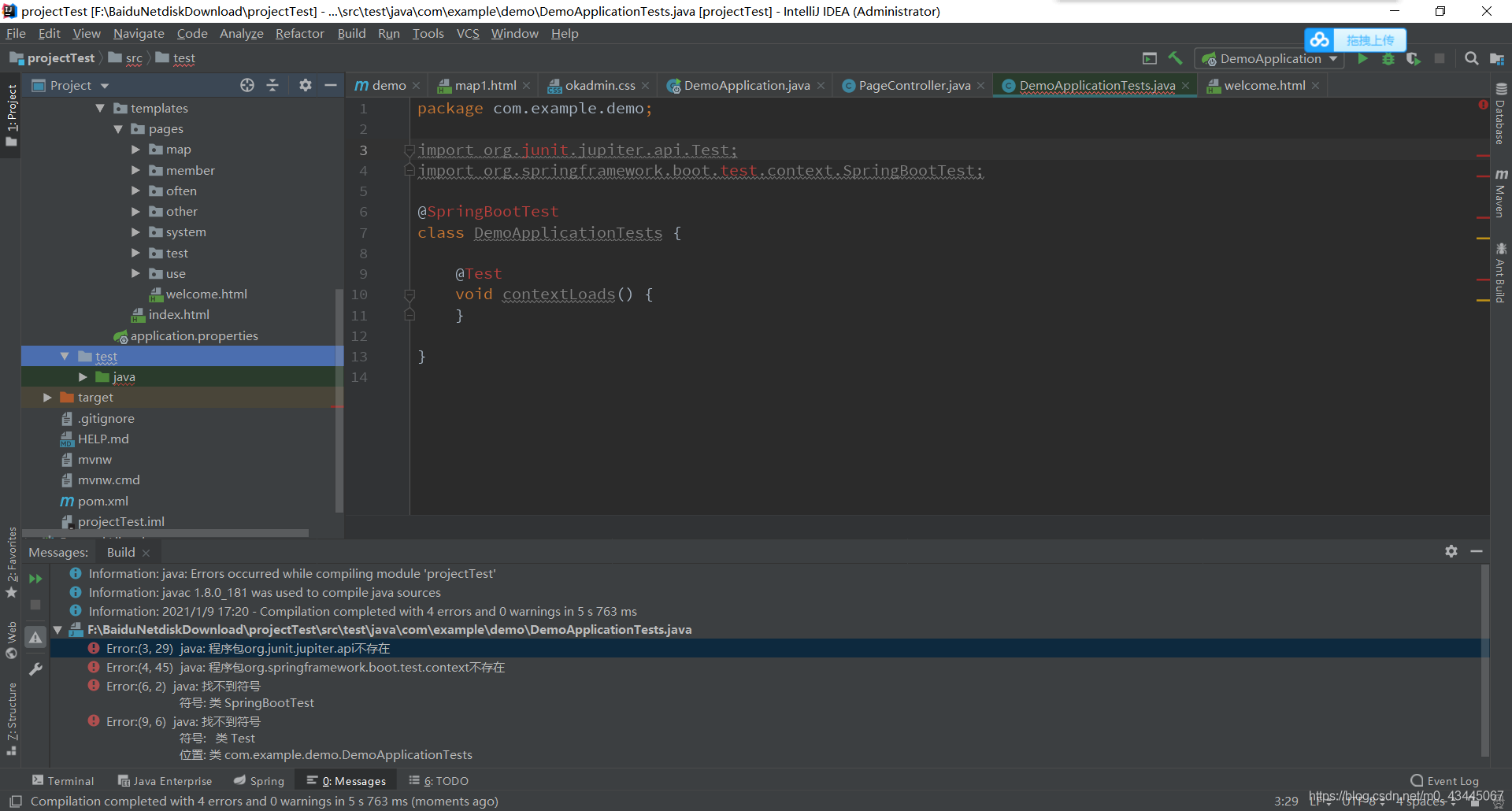
只需要删除相应Test文件即可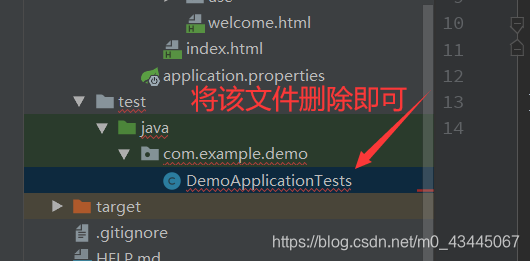
编写相应的Controller 写页面跳转即可
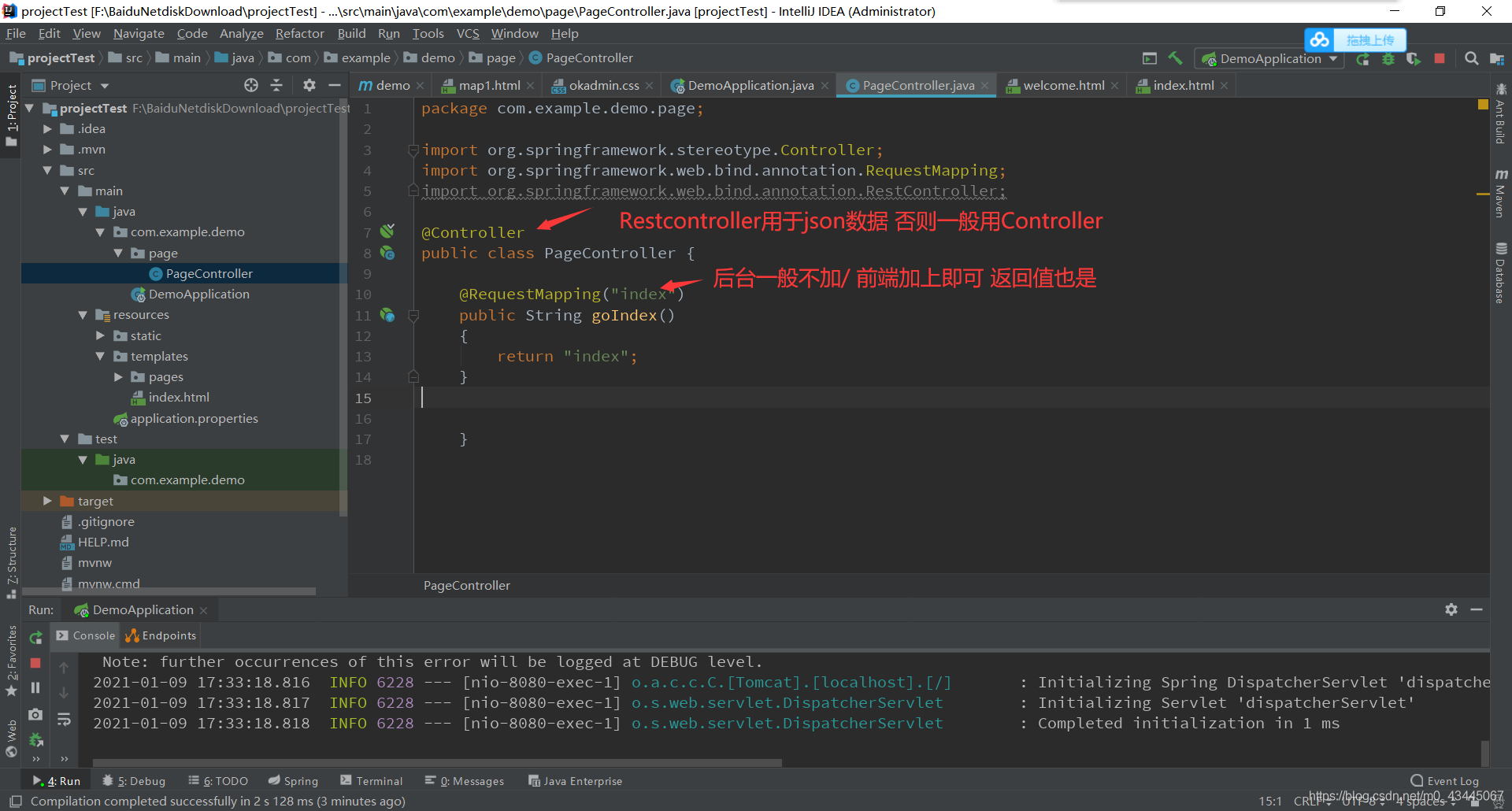
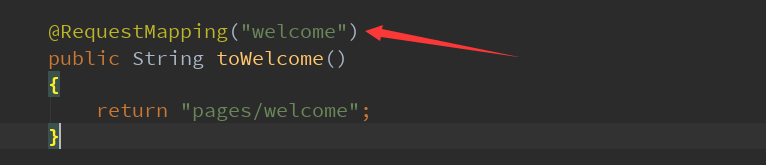
则比如:iframe标签中,src属性为welcome
那么写一个Controller RequestMapping参数为”welcome” 直接返回相应的前端页面即可 避免404
看图:

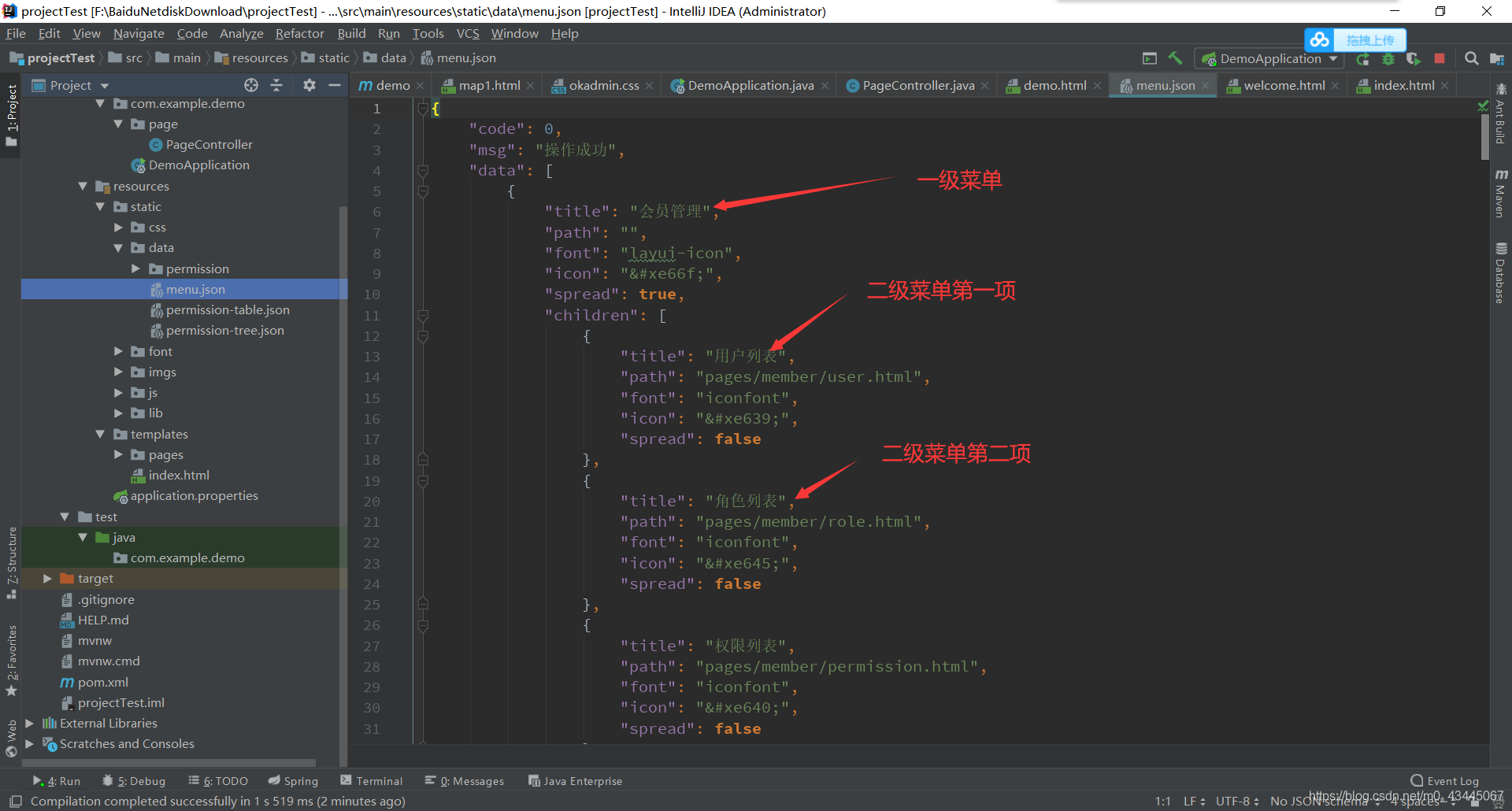
大致页面如下:
localhost:8080 或者 localhost:8080/index (默认欢迎页面为Index)
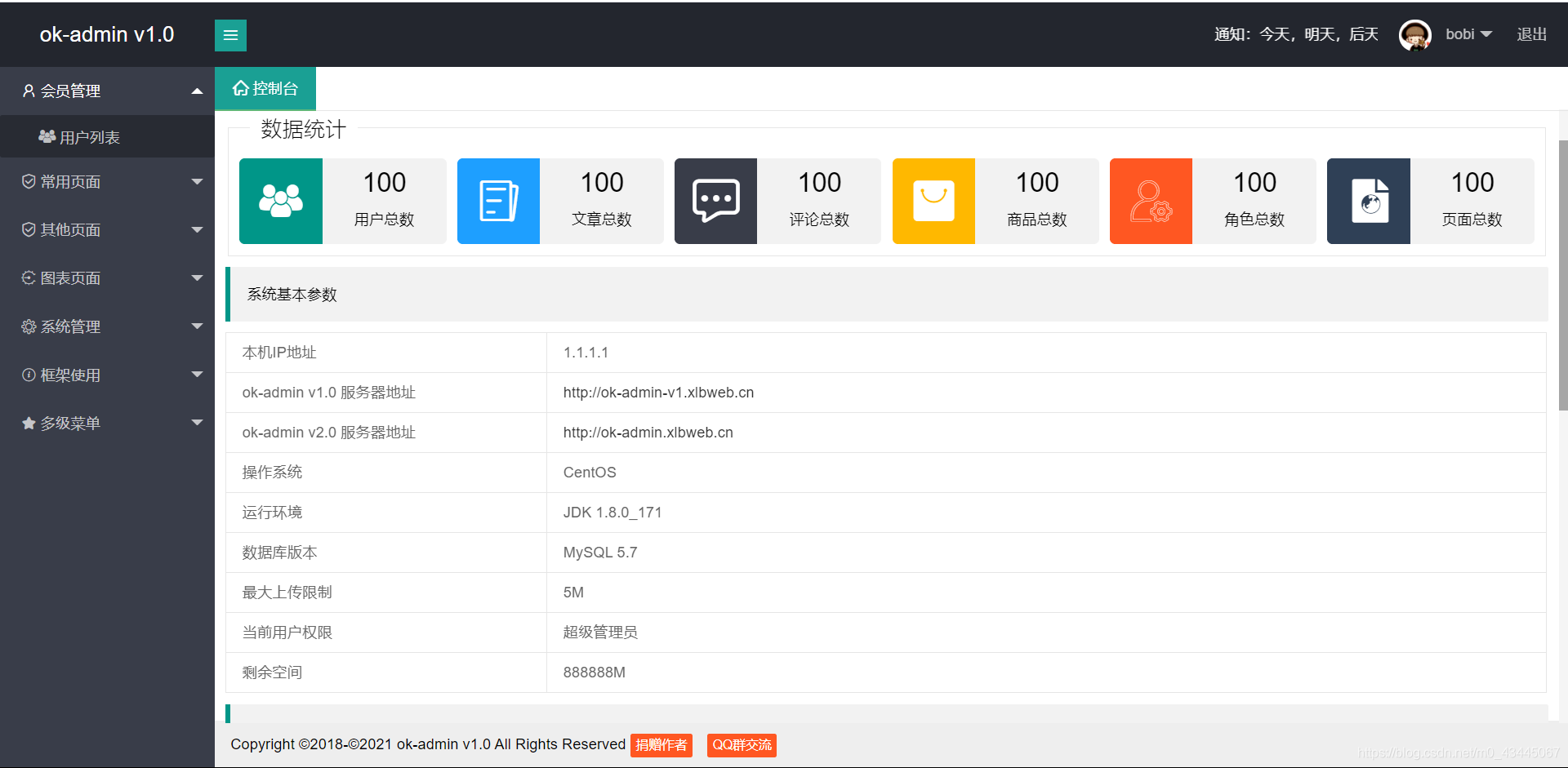
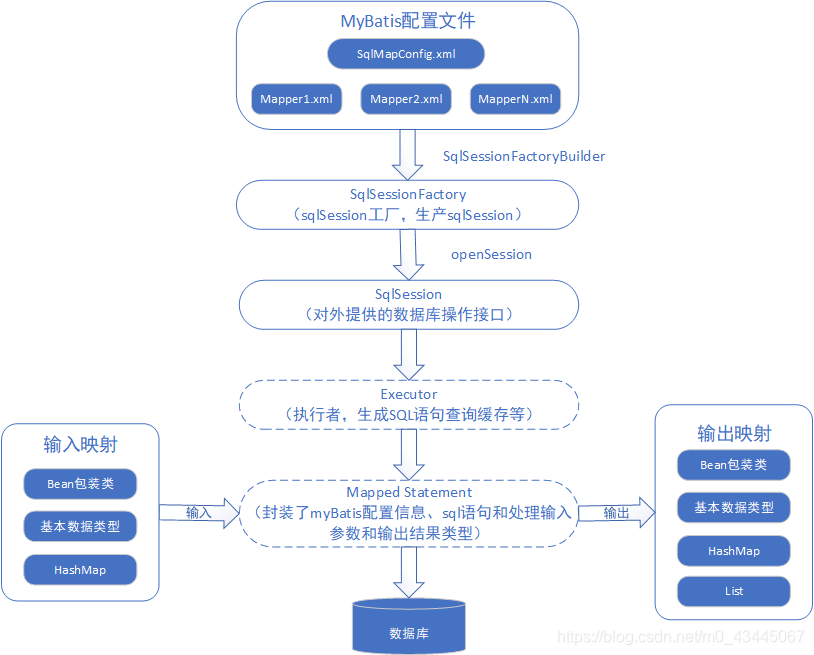
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code, 并且改名为MyBatis 。2013年11月迁移到Github。MyBatis是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。 MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。总而言之MyBatis是一个轻量级简化数据库操作的框架。
1 |
|
注意:
当使用<package/>标签时 映射接口文件与映射配置文件共同应该在Mapper文件夹下
否则使用mapper标签 且用resource指定对应的配置文件所在目录
1 |
|
1 | package com.sikiedu.mapper; |
1 | package com.sikiedu.bean; |
1 |
|
1 | String resource = "sqlMapConfig.xml"; |
Mybatis的调用过程中:
1 | ....忽略配置文件加载、SQLSession建造者、工厂.... |
1 | ....忽略配置文件加载、SQLSession建造者、工厂.... |
1 | ....忽略配置文件加载、SQLSession建造者、工厂.... |
1 | <!-- type表示具体的Java类 id随便取-唯一标识即可 --> |
比如一个用户User 有多个帖子Post
现在查询对应的User 查看这个User下的所有帖子(因此帖子是集合java private List<Post> posts;)
1.User类
1 |
|
2.Post类
1 | public class Post implements Serializable{ |
3.ResultMap配置一个用户多个帖子的映射
1 | <!-- 在一个User中配置 多个collection --> |
4.SQL语句
1 | <!-- 指定结果映射为resultUserMap 需要跟相应resultMap标签的id相同 --> |
2021.4.6更新:
起别名代码:
1 | <select> |
注意,这里的代码指的是:
1. DAO层的XXXMapper.java接口
2. DAO层的XXXMapper.xml文件
3. Model层的XXXExample.java类 方便提前处理数据
1 | <plugin> |
项目结构图:
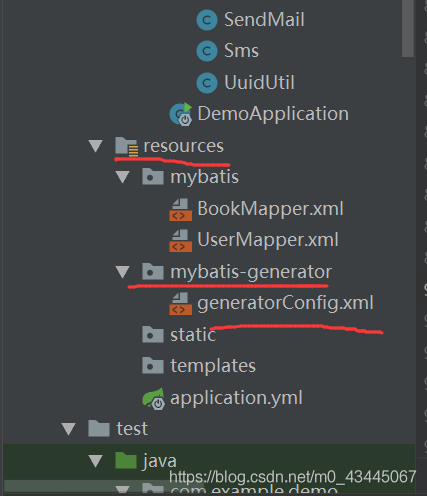
这一步很关键,要避免多次生成重复的BaseResultMap
注意对应Mapper.java/ Mapper.xml在项目结构图中的位置
1 |
|
注意,在集成SpringBoot时
首先确保 UserMapper.java要有@Mapper注解
其次,要注意在SpringBoot配置文件application.yml中:
1 | mybatis: |
并且项目结构图如下: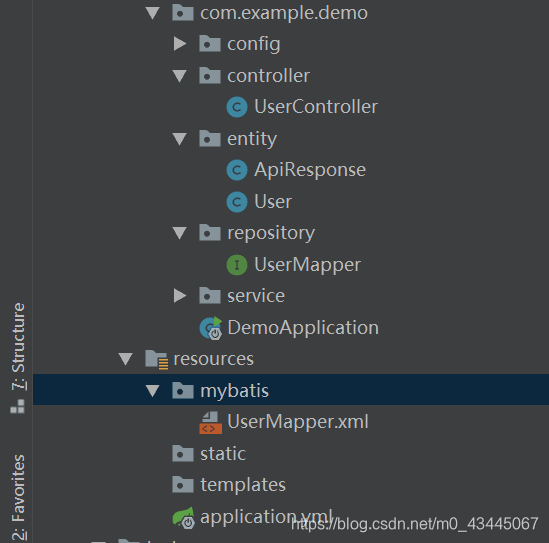
或者代码generator生成的配置文件中配置
1 | <mapper namespace="com.example.demo.repository.UserMapper"> |
1. 尽量让实体类中的各个private属性名字与数据库的字段名字相同
2. 用封装类!不要用int,而是应该用Integer
3. 如果实体类中的属性名与数据库中的字段名相同,这样mapper中参数为实体类时,才能返回
考研英语分为英语一与英语二,其中英语一多为学术型研究生而准备,而英语二多为专业型研究生而准备。本文旨在总结考研一路走来自己对英语二学科的重要总结以及经验之谈,比较适合在经过一段真题复习之后抓重点、查漏补缺!希望阅读到本文的你能够有所得。Respect!
完形填空,一直都是大家不重视的科目,毕竟所占的分数不多,才 “十分”,但是非常重要!(请大家务必重视完形的做题方法)万事开头难,完形也不例外。
Without further ado 废话不多说,我们直接进入正题~
以下笔记以及方法论,自己总结归纳众多名师(其实没怎么看他们本人的课,都在各个网络渠道微博,知乎,哔哩哔哩等看到的方法哈哈哈)
完形填空我建议同学去读读 刘晓燕老师的《真题就这么点儿事》 与有道的赵楠楠老师的相关教学,正文开始!
例如:(2015年英语二文章)
==In our contemporary culture== , the prospect of communicating with-or even looking at- a stranger is virtually unberable. ==Everyone== around us seems to ==agree== by the way they cling to their phones, even without a __ on a subway.
第一句指出,当代文化(=大众 everyone)认为,与陌生人交谈,甚至看向陌生人都是不可忍受的, // 而作者的观点, 大多“反对”大众文化。
我们看看第二段怎莫硕呢:
==It’s a sad reality== —our desire to avoid interacting with other human beings—because there’s___to be gained from talking to the stranger standing by you.
“sad”表明作者对此观点表示批判(小技巧:附有鲜明态度的形容词,一般很好地体现出作者的态度),同时==表明自己的观点(与大众相反即可):看向陌生人,与陌生人交谈其实没那么难以忍受。==
在知道作者的观点与态度或者文章的主旨句之后,再去斟酌每个选项,也许可以从更宏观的方面去把握更正确更优的答案。
我们再来看个例子:(2013年英语二文章)
Given the advantages of electronic money,==you might think== that we would move quickly to the cashless society in which all payments are made electronically. ___, a ==true== cashless society ==is probably not around the corner==.
如出一辙,you might think = 大众的观点,即认为很快会进入“无纸化社会”,而后提到真正的无纸化社会也许还没有到来,明显提出自己的观点。因此,全文的选项,选择时都应该按照 无纸化不会到来 这个大方向来做。
The drive to discover is deeply rooted in humans, much the same as the basic drives for __ or shelter.
该文章主要说明:为什么人们总是在网上浏览很负能量的评论,做一些明显很令人痛苦的事情。因为人们习惯去解决“不确定”,可能明知到事情的答案,还是想满足自己内心的好奇心。
而聚焦到问题,说人类探索未知的渴求,如同探求__或避难所(庇护)一样,或者所连接的前后意思相近
A.Food (食物) B.pay(工资) C.Marriage(婚姻) D.schooling(学校教育)
根据排除法和常识,我们可以确定答案选 A,与 shelter 避难所含义相近。
譬如active 与 alive 也是具有相同意义的词语。
若文章的中心是反对战争支持和平,那么若某一细节处出现 *** ___war *** 选项中优先考虑 against等表示反对的介词.
Given the advantages of electronic money,==you might think that we would move quickly to the cashless society in which all payments are made electronically.== ___, ==a true cashless society is probably not around the corner==.
您也许会认为我们很快会进入无纸化社会,但是真正的无纸化社会也许可能不会很快来到。根据插入语(即填空处)前后的逻辑关系,属于虽然但是(让步状语从句),且转折处为作者观点,是重点!聚集选项:
A. However (然而)
B. Moreover (而且)
C. Therefore (因此)
D. Othervise (否则)
同样地,对于:
1.总分结构再次强调作者观点句的:For instance, for example,

Dishonest persons 可能会进入电子支付系统并__某人的账户,本文所讲的是无纸化社会不会到了,也就是说作者对无纸化社会的态度是negative的,因而我们首先判断这个动词的褒贬方向:是好的方向,还是坏的方向; 既然针对 “electronic payments system” 那么代表坏的方向,因而我们聚焦到选项:
A. 偷窃,盗取
B. 选择
C. 使受益
D. 返回,收益(pl)
了解到出题者的用心良苦后,我想答案不言而喻。

文章在此处阐述,与其与陌生人交谈,倒不如自己在乘车时独自闭口不谈,而在经历实验之后,大家没有觉得 “与陌生人交谈”让人尴尬。
聚焦选项:
go through with 经历 do away with 终结,废除 catch up with 追赶 put up with 容忍,忍受
这里用put up with是不恰当的,因为受实验者并没有完全谴责或者反对与陌生人交谈的行为。因为使用经历较好。
利用上文五大点,无论是宏观把握还是细节斟酌都能很好地选出最优答案,剩余的事情,就是从反复研读历年真题。找出选项与所在处前后的共性,不断总结归纳常考词汇。
基础不太好的同学,建议跟相关老师的视频课,撇开阅读而谈词汇: 朱伟老师的词汇课挺不错的!何凯文老师的必考词汇也不错,有些推荐的单词是专八系列。从词汇本身的难度而言,是比较好的,附有相近词与例句。 建议基础较好的同学,可以不用听专门的词汇课,本人反复看《十天搞定考研词汇》再辅佐历年真题(真题词汇,建议自己总结!!!),可以达到一样的效果,
阅读方法正文:(本段以历年真题为例子)
考研阅读板块,我建议跟名师:
1.有道唐迟老师、赵楠楠老师
2.前文都、现新文道教育何凯文老师
唐迟而言,串联题干而避免选项干扰 是对锁定文章内容、排除错误方向起着重要作用的。
看完选项后,根据零散的记忆,是否可以推测以下大致围绕什么主题讲。 经济?社会问题?现象?文化板块….
直接上题:2020年英语二真题Text1
第一问: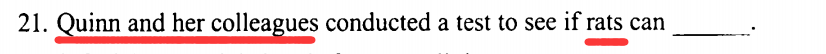
第二问:
第三问:
第四问:
第五问:
总览所有选项,几乎不离 Rat 老鼠 and Robot 机器人(文中的机器鼠) 单词,因而我们在读完题目之后。思考:
本文或许是阐述,有关于老鼠的实验,从实验中,我们应该找到:
1.具体人物表达的观点或态度
2.作者的态度/若无明显态度,则作者不反对的态度基本与作者态度一致
熟悉吗?没错,就是完形填空的第一步!精读文章第一段,再对文章大致主题的主观推测基础上,用作者自己的话再次佐证文章的中心话题。譬如本文第一段:
第一句中,挑出比较重要的部分,to attuned to 意为 “ 适应,调整 或 对…敏感”。因此,开篇提到老鼠对社会信号高度敏感,以此来认清敌友。 因此纵观全文,作者应探讨老鼠与 “社会信号” 的关系。
再比如:2018年英语二Text2
这种以 “while” 引导的让步状语从句,是考研长句中比较普遍的句式。while 此时作 “尽管,虽然” 的意思,从句不重要!重要的是主句,即逗号后面的内容(未来属于例如风能、太阳能等新能源)这一句同时也是文章围绕讲的内容。因此作者既然说出来了未来是属于新能源的,那么作者对新能源应持正面,支持的态度!
1.主旨题, 2.细节题, 3.例证题 4.态度题
凡是不属于主旨题(中心思想,文章题目,文章大致内容)、例证题(某某例子说明什么?作者通过xx想表达什么?)以及态度题(不管是作者还是出现的某某某)的,都归于细节题,从文章某处本身上下文寻找最优答案。
看几个例子:
做法因人而异,但个人觉得比较适合大家的是:
1.通读全文,一顿勾勾画画
2.定位到相应的句子,读懂句子,联系中心!!!
3.找选项中错误的句子,找与关键句子同意替换的表达式
4.与文章中心靠拢!排除与中心相反或根本无关的句子
其中,2,3,4,是较为困难的过程,同时需要大量的反复练习。揣摩到底这个选项是不是符合中心内容的,是不是对的?哪里有相应同意的表达句,或者是不是正话反说?(出现过,概率不大)
仍然聚焦 2020年英语二 Text1: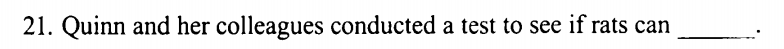
Q与同事对老鼠进行测试是想看看老鼠是否会___?
明显属于细节题,看文章内容:
其中,蓝色划线句是文章背景句。而红色划线句是相应重点句,文章说:为了看看这种敏感程度是否会延伸到 “非动物”身上即:(老鼠是否会对来自机器鼠的社交信号而敏感),因而与选项中比对,是否有与其同意表达的,排除与中心内容无关的,排除说法相反的。
选项:
答案一定是来自文章的句子的,绝不是经过主观理解臆断出来的。 这是考研英语阅读不变应万变的宗旨。因而,A选项提到是否老鼠能够获得来自“机器鼠”的社交信号 ,即是细节句的同意表达。因而正确!因为是细节句的同意表达,因而在A选项的存在情况下,其他选项不具备更优答案的气质。
再举个例子:
2020年 Text4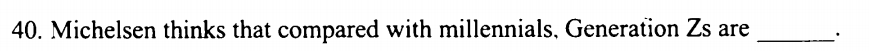
M认为,相比较于 millennials(千禧一代) ,Z世代比较___?
根据定位出题处,
** 注意:题中问的Z世代如何?因此选项中可以排除千禧一代所具有的特点(flexible)。而文中提到因为零工经济 (gig economy) Z世代者寻求更多的确定性、稳定性 ,有这一关键句就够了。从选项中找“确定性” “稳定性” 的同义词,同时排除相反的词。聚焦选项:

A 更加勤奋 (中心无关)
B 更加慷慨(同理)
C 没那么追求实际 (相反含义应排除,因为正是零工经济,所以追求实际情况)
D 没那么冒险、比较谨慎 (more certainty、stability 的同义词 = 谨慎,不冒险)
因此,该类型的题目的核心点: 答案文中找,不找无关的,找同意替换、更贴近中心的。
相信听过唐迟老师课程的同学都知道, 例子不重要,重要的是例子所欲支撑的观点。 没错,我们的目的就是找例子前后的观点。说来简单,做来实属不易。
举个例子:2019年Text2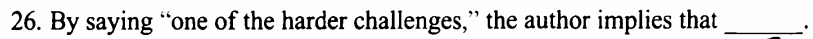
作者谈到 “艰难的挑战之一” ,何意?
回归文章:

句子很长,内容比较多。但是挑出与题目更直接相关的内容。可以看到,开篇作者提出森林给了我们庇护,给了我们在应对环境变化中出现的艰难挑战 ,fight against climate change 是好事情啊,为何提到是 challenge 挑战呢?原来,The climate change 会使得森林排放比自身吸收得更多的碳元素 = 入不敷出 ,因而有了这一关键句就够了。做题时,抓住好事会变成坏事,找森林给了我们艰难挑战的同意表达:

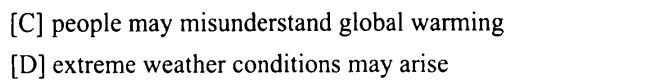
相比较而言,森林给了我们艰难挑战对应同意表达的选项是
【B】forests may become a potential threat 森林有可能成为潜在的威胁 = 艰难挑战 = 排放出多于自身吸收的碳元素
再看一个例子:2021年 Text 2

L大学的报告显示,在英国,____
回归文章:

划线句子是关键句,根据报道,在英国,全国85%的土地与肉产品、奶制品直接相关。 读文章时,有些必要成分是一定要揣摩的,比如 “数字” “书名号” “感叹号” 作者不会无缘无故提到数字,不会无缘无故地提到某书的命名,同时也不会无缘无故地感叹、发表观点。
比如这里,文中出现 85% ,心中就要想,这个数字代表什么?想要强调什么?好事还是坏事?会不会与作者态度相关?
找到关键句后,回归选项:
[A] farmland has been inefficiently utilised
[B] factory style production needs reforming
[C] most land is used for meat and dairy production
[D] more green fields will be converted for farming
因而经过关键句的同意表达:85% percent = most land 再三斟酌,可以选出正确答案 C选项。
文章的主旨就是整个文章的心脏,文章主旨当然大部分是与作者观点态度直接相关的。因而,做文章时,应首先明确自己的做题目标:
①、文章主旨/文章中心
②、作者观点(是否相同/相反)
这一块我还是力挺唐迟老师的做法:回文法。
如果给你ABCD四个标题,或者四个文章主旨,你会怎么写文章?
例如:2016年text3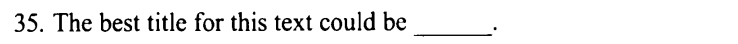
直接看第一段,思考中心话题

每个人都太忙了,这已经是Cliche(陈词滥调,老生常谈)了。而抱怨声尤其来自:没时间阅读。 至此,我们已经可以猜测到,这篇文章是讲没时间阅读这个现象,作者一定会围绕这个中心话题展开探讨。

因而,答案一目了然。 How to Find Time to Read 如何空出时间来阅读? 这不就是中心话题吗?反过来说,如果是命题作文:如何空出时间阅读?
第一步当然就是陈述现象!阐述随着当今世界发展,越来越多的人哀嚎:没有时间阅读。然后继续行文…
再举个例子:

问作者态度,针对英国政府目前在运动方面所作出的努力。
回归文章:

The Parkrun phenomenon 本地公园跑现象的成功,更加凸显伦敦奥运遗风的失败!,为全文点出批评英国政府的总基调。作者提到:十年前,Planning documents 承诺人们会更苗条,更健康,然后事情并不如人意,Officials 并没有激励新一代更多地参与体育!
聚焦选项:
A 忍受,容忍
B 批判,批评
C 不确定的
D 同情的
根据作者所表达的态度,伦敦奥运遗风的失败! 批评英国政府的总基调, Officials 并没有激励新一代更多地参与体育! 我们可以确定,作者对英国政府持批评态度!
为什么这么说?很简单,不管是小标题题型(每段话缺标题,给出若干个标题,一一对应)

还是概括句题 (文章后有一个表格,将左边的事物与右边的表述一一正确对应)

均是在在阅读文章,完全理解了文章之后!对阅读到的信息进行归纳总结。
新题型板块,我建议:
有道赵楠楠老师
可以说对于两种题型,方法大同小异:
1.定位
2.找同义替换
3.回归选项
带着做题思路做真题,例如2018年小标题题型,放出链接如下:
第一步:读选项,混个眼熟
第二步:读文章标题
第三步:直接聚焦相应段落:找段落重要句
该文章的标题: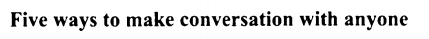
与人交谈的五种方法

红色是关键句,作者提到:
I know the feeling and here is my advice: just get it (想说的话) out. 读完回归众多选项,进行同义替换:

Just say it = Just get it out 同意替换,因此相比之下,A为正确答案
再比如:

Find the things which you and that person have in common 说白了就是找到你与交谈对象所具有的共同点!找到共同点后,两人才能建立connection,才能使得谈话更顺利!
聚焦选项,找与表达 “找共同点” 的同义替换:

再三斟酌,Find the “me too”s = have in common 能够形象地表达出共同点!因而,E成为正确答案。
翻译是可以说是,英语学科中,最难也是最重要的板块!这个板块中,我建议
前新东方名师,现跟谁学名师-教翻译的唐静老师
唐静老师所讲授的知识点特别他的《拆分与组合》,能够从根本上解决无法对句子进行长句断翻、短句补译、整理中英译法之差别等技巧。踏踏实实学翻译。
我建议:
1.跟唐静老师学视频课
2.利用学到的技巧,用在历年阅读真题上,精读文章中的句子!
作文板块,我推荐王江涛老师的《考研英语高分写作》,基础不好的同学需要听王江涛老师的视频课,反复听!较好的有该书即可,并辅佐自己平时的总结!英语作文范文不在于多,而在于精,因此我建议范文处理方法:
最后,利用已有反复诵读的范文模板,尝试去做新题,输出学到的相应必备句型!模板的作用是在于用,不在于记!因而,要多用,否则考场上也无法很快地进入状态。
1 | int main(){ |
1 |
|
int main(){
1 | int a, b,max; |
1 |
|
1 | int main(){ |
1 | int main(){ |
1 | int fib(int n){ |
1, 1, 2, 3, 5…以此类推
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|

1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 | ### 第二章: |
1 |
|
1 | 第五章: |
1 | 第六章: |
1 | 6.9: |
1 |
|
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-element
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
作者:Xiaohu9527
链接:https://leetcode-cn.com/problems/remove-element/solution/cyi-ci-li-bian-bu-xu-yao-bao-li-gan-jue-82cz7/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
给你一个字符串 s,由若干单词组成,单词之间用空格隔开。返回字符串中最后一个单词的长度。如果不存在最后一个单词,请返回 0 。(注意本题最后 可能出现连续的空格)单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = “Hello World”
输出:5
示例 2:
输入:s = “ “
输出:0
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/length-of-last-word
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | int lengthOfLastWord(string s) { |
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/climbing-stairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | //一定看懂本题的动态规划 |
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。 (本来都有序,想要合并之后仍有序)初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。你可以假设 nums1 的空间大小等于 m + n,这样它就有足够的空间保存来自 nums2 的元素。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/merge-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/search-insert-position
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
示例 1:
输入:19
输出:true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
示例 2:
输入:n = 2
输出:false
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/happy-number
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
1 | class Solution { |
统计所有小于非负整数 n 的质数的数量。
示例 1:
输入:n = 10
输出:4
解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
示例 2:
输入:n = 0
输出:0
示例 3:
输入:n = 1
输出:0
1 | class Solution { |
给定一个整数数组,判断是否存在重复元素。
如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例 1:
输入: [1,2,3,1]
输出: true
示例 2:
输入: [1,2,3,4]
输出: false
示例 3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true
1 | class Solution { |
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。
示例:
输入: 38
输出: 2
解释: 各位相加的过程为:3 + 8 = 11, 1 + 1 = 2。 由于 2 是一位数,所以返回 2。
1 | class Solution { |
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = “hello”, needle = “ll”
输出: 2
示例 2:
输入: haystack = “aaaaa”, needle = “bba”
输出: -1
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/implement-strstr
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
示例 1:
输入: 1->1->2
输出: 1->2
示例 2:
输入: 1->1->2->3->3
输出: 1->2->3
1 | /** |
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:[“h”,”e”,”l”,”l”,”o”]
输出:[“o”,”l”,”l”,”e”,”h”]
示例 2:
输入:[“H”,”a”,”n”,”n”,”a”,”h”]
输出:[“h”,”a”,”n”,”n”,”a”,”H”]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个赎金信 (ransom) 字符串和一个杂志(magazine)字符串,判断第一个字符串 ransom 能不能由第二个字符串 magazines 里面的字符构成。
如果可以构成,返回 true ;否则返回 false。
(题目说明:为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思。杂志字符串中的每个字符只能在赎金信字符串中使用一次。)
示例 1:
输入:ransomNote = “a”, magazine = “b”
输出:false
示例 2:
输入:ransomNote = “aa”, magazine = “ab”
输出:false
示例 3:
输入:ransomNote = “aa”, magazine = “aab”
输出:true
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/ransom-note
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:
s = “leetcode”
返回 0
s = “loveleetcode”
返回 2
提示:你可以假定该字符串只包含小写字母。
1 | class Solution { |
给定一个包含 [0, n] 中 n 个数的数组 nums ,找出 [0, n] 这个范围内没有出现在数组中的那个数。
示例 1:
输入:nums = [3,0,1]
输出:2
解释:n = 3,因为有 3 个数字,所以所有的数字都在范围 [0,3] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 2:
输入:nums = [0,1]
输出:2
解释:n = 2,因为有 2 个数字,所以所有的数字都在范围 [0,2] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 3:
输入:nums = [9,6,4,2,3,5,7,0,1]
输出:8
解释:n = 9,因为有 9 个数字,所以所有的数字都在范围 [0,9] 内。8 是丢失的数字,因为它没有出现在 nums 中。
示例 4:
输入:nums = [0]
输出:1
解释:n = 1,因为有 1 个数字,所以所有的数字都在范围 [0,1] 内。1 是丢失的数字,因为它没有出现在 nums 中。
提示:
n == nums.length
1 <= n <= 104
0 <= nums[i] <= n
nums 中的所有数字都 独一无二
1 | class Solution { |
给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。
示例 1:
输入:[3, 2, 1]
输出:1
解释:第三大的数是 1 。
示例 2:
输入:[1, 2]
输出:2
解释:第三大的数不存在, 所以返回最大的数 2 。
示例 3:
输入:[2, 2, 3, 1]
输出:1
解释:注意,要求返回第三大的数,是指在所有不同数字中排第三大的数。
此例中存在两个值为 2 的数,它们都排第二。在所有不同数字中排第三大的数为 1 。
提示:
1 <= nums.length <= 104
-231 <= nums[i] <= 231 - 1
1 | class Solution { |
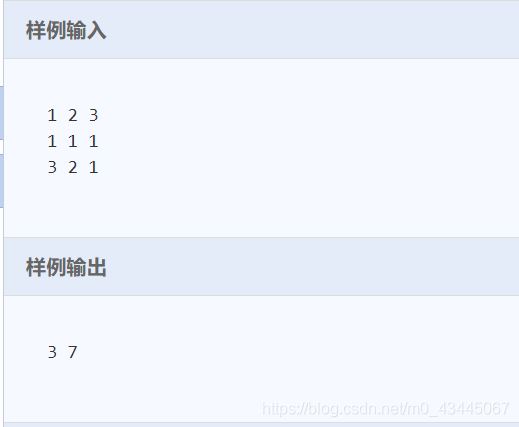
题目描述
有一头母牛,它每年年初生一头小母牛。每头小母牛从第四个年头开始,每年年初也生一头小母牛。请编程实现在第n年的时候,共有多少头母牛?
输入
输入数据由多个测试实例组成,每个测试实例占一行,包括**一个整数n(0<n<55)**,n的含义如题目中描述。
n=0表示输入数据的结束,不做处理。
输出
对于每个测试实例,输出在第n年的时候母牛的数量。
每个输出占一行。
1 |
|
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
输入: “Hello, my name is John”
输出: 5
解释: 这里的单词是指连续的不是空格的字符,所以 “Hello,” 算作 1 个单词。
1 | class Solution { |
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
示例 1:
输入:s = “abc”, t = “ahbgdc”
输出:true
示例 2:
输入:s = “axc”, t = “ahbgdc”
输出:false
提示:
0 <= s.length <= 100
0 <= t.length <= 10^4
两个字符串都只由小写字符组成。
1 | class Solution { |
给定一个字符串来代表一个学生的出勤记录,这个记录仅包含以下三个字符:
‘A’ : Absent,缺勤
‘L’ : Late,迟到
‘P’ : Present,到场
如果一个学生的出勤记录中不超过一个’A’(缺勤)并且不超过两个连续的’L’(迟到),那么这个学生会被奖赏。
你需要根据这个学生的出勤记录判断他是否会被奖赏。
示例 1:
输入: “PPALLP”
输出: True
示例 2:
输入: “PPALLL”
输出: False
1 | class Solution { |
URL化。编写一种方法,将字符串中的空格全部替换为%20。
假定该字符串尾部有足够的空间存放新增字符,并且知道字符串的“真实”长度。
(注:用Java实现的话,请使用字符数组实现,以便直接在数组上操作。)
示例 1:
输入:”Mr John Smith “, 13
输出:”Mr%20John%20Smith”
示例 2:
输入:” “, 5
输出:”%20%20%20%20%20”
1 | class Solution { |
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
示例 1:
输入: “abab”
输出: True
解释: 可由子字符串 “ab” 重复两次构成。
示例 2:
输入: “aba”
输出: False
示例 3:
输入: “abcabcabcabc”
输出: True
解释: 可由子字符串 “abc” 重复四次构成。 (或者子字符串 “abcabc” 重复两次构成。)
1 | class Solution { |
给出 N 名运动员的成绩,找出他们的相对名次并授予前三名对应的奖牌。
前三名运动员将会被分别授予 “金牌”,“银牌” 和“ 铜牌”(”Gold Medal”, “Silver Medal”, “Bronze Medal”)。
(注:分数越高的选手,排名越靠前。)
示例 1:
输入: [5, 4, 3, 2, 1]
输出: [“Gold Medal”, “Silver Medal”, “Bronze Medal”, “4”, “5”]
解释: 前三名运动员的成绩为前三高的,因此将会分别被授予 “金牌”,“银牌”和“铜牌” (“Gold Medal”, “Silver Medal” and “Bronze Medal”).
余下的两名运动员,我们只需要通过他们的成绩计算将其相对名次即可。
1 | class Solution { |